

Economic Surveillance using Corporate Text
Over the past decennium, we have witnessed a significant growth in the volume of company-released text data, ranging from transcripts of periodic earnings calls—in which company management discusses their firms’ financial performance, future outlook, and strategic initiatives—to an extensive array of regulatory filings required of companies traded on U.S. stock exchanges. Economists are increasingly recognizing its potential as a powerful resource for economic analysis and insights.
In our article, we discuss how to apply various computational linguistics tools to analyze unstructured texts provided by firms, uncovering how markets and firms respond to economic shocks—whether caused by a natural disaster or geopolitical event—offering insights often beyond the scope of traditional data sources. We highlight examples of corporate-text analysis, including earnings call transcripts, companies’ patent documents, and job postings.
By integrating computational linguistics into the analysis of economic shocks, this approach offers new possibilities for generating real-time economic data and providing a deeper understanding of firm-level reactions in volatile economic conditions—termed here as “economic surveillance.” Notably, it can cover not only current events as they unfold but also measure past expectations surrounding historical events, overcoming the challenges faced by surveys that attempt to reconstruct pre-event expectations retrospectively.
In parallel with the relentless flow of corporate text, the field of computational linguistics has made significant strides, developing tools that facilitate the measurement of various text dimensions, including, but not limited to, sentiment, topic, and perceived risk or uncertainty. For instance, when examining a specific economic shock—such as Brexit, the UK’s decision to leave the European Union—discussions centered on that topic can be filtered to assess the associated sentiment or perceived risk and uncertainty. In the article, we delve into each of these dimensions and illustrate their use through an empirical application.
To illustrate, measuring Brexit risk (i.e., risks induced on firms’ strategies and operations due to Brexit) this way enables direct comparisons across different sources of risk, providing valuable insights in various contexts. To see how this works, note that the axis in Figure 1 uses directly comparable units, presenting the percentage of total sentences in earnings calls. For example, in 2016Q3, publicly listed firms worldwide averaged 6.85 sentences discussing risks, of which 0.098 were related to Brexit. This indicates that Brexit accounted for 1.43% of all risk-related discussions during that period.
Figure 1: Discussions related to Brexit risk in earnings calls
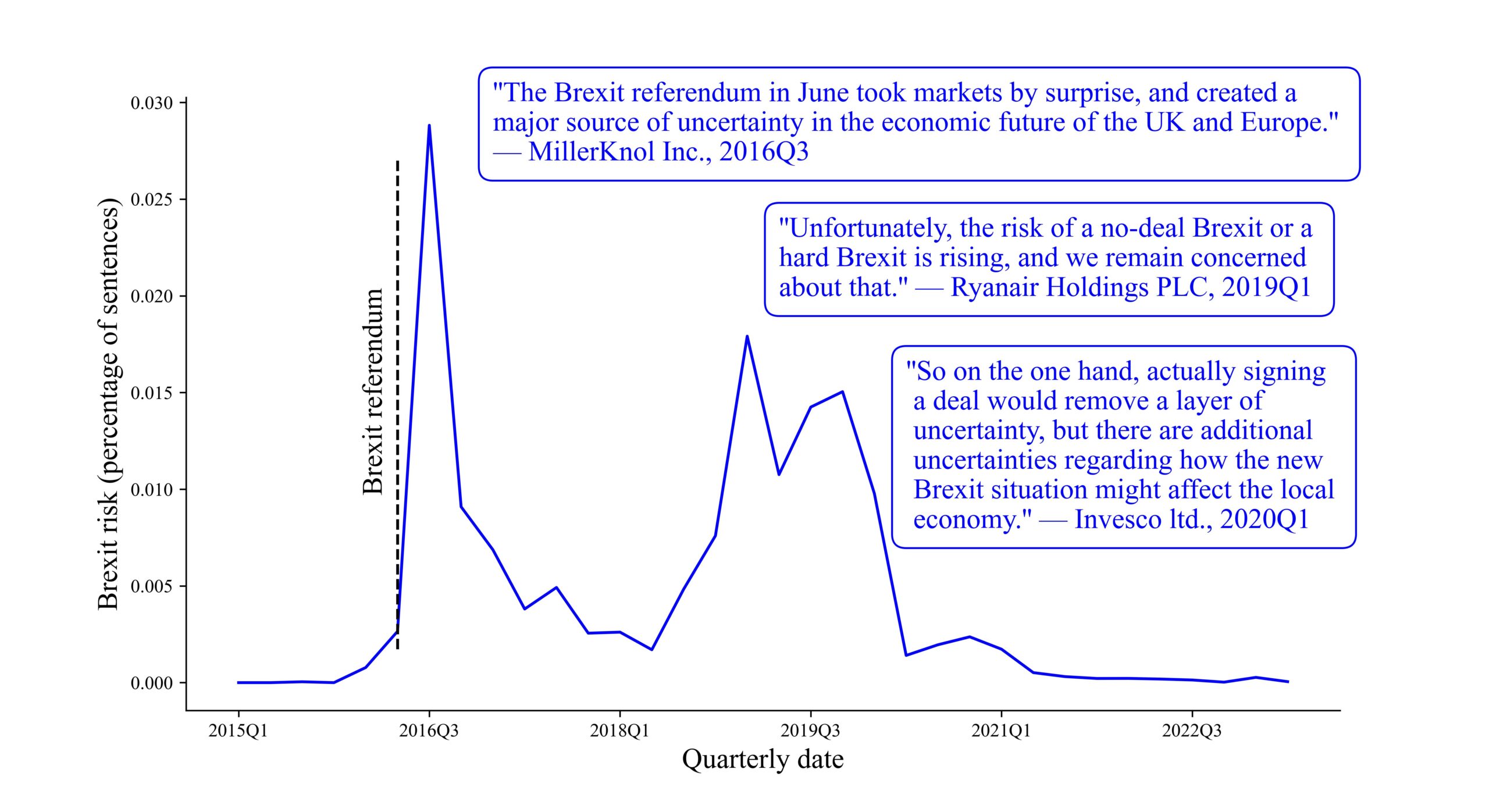
This cardinal decomposition enables to allocate a portion of overall risk to specific sources by comparing the amount of time (number of sentences) spent discussing risks related to specific topics in earnings calls. Figure 2 illustrates this approach.
Figure 2: Decomposing specific risks discussed in earnings calls
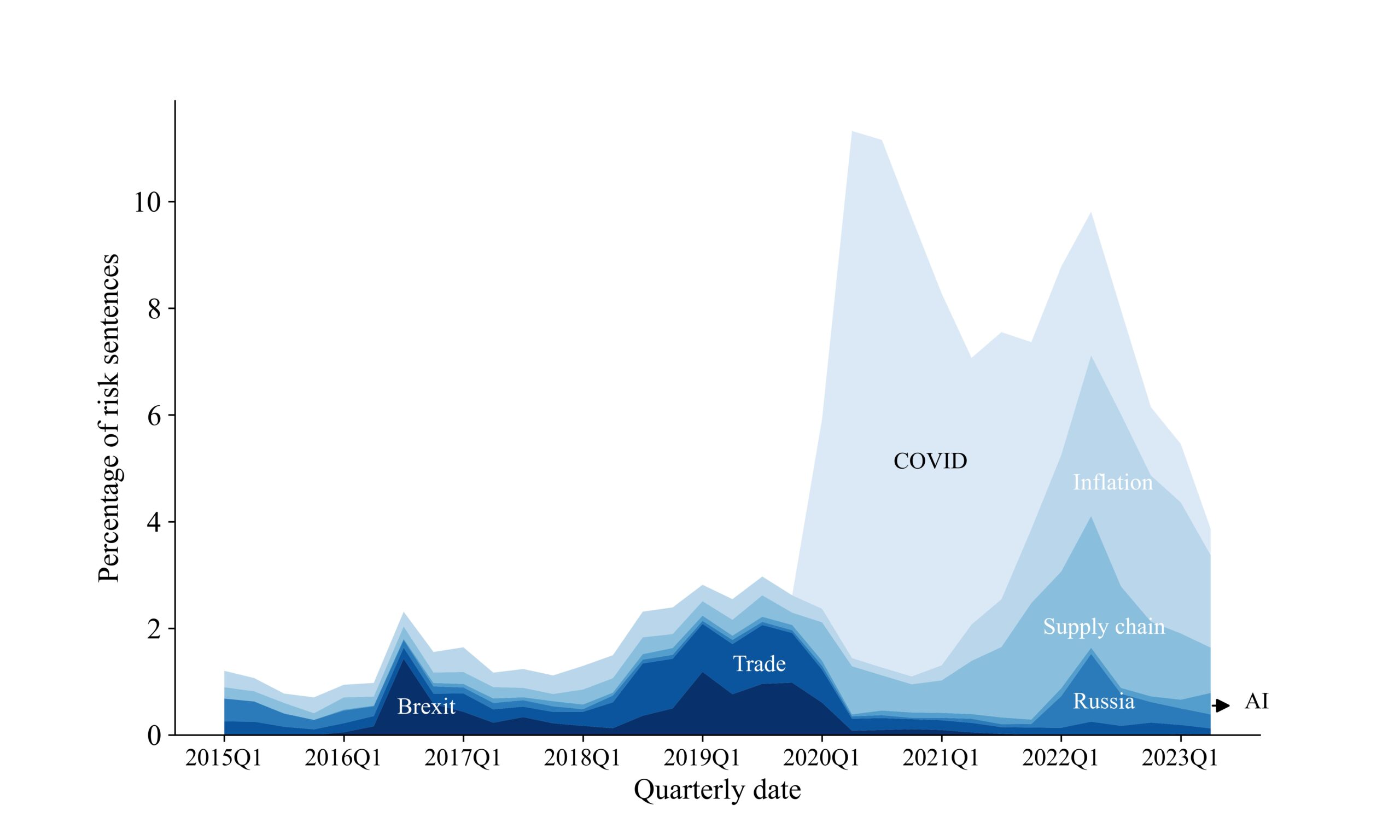
Specifically, it shows the share of risk-related sentences attributed to Covid-19, inflation, supply chain disruptions, Brexit, trade policy, Russia, and artificial intelligence (AI). Trade policy risk peaked during the first Trump administration, reaching approximately 0.98 percent of risk mentions in 2018Q3, a level comparable to Brexit’s impact. The Covid-19 crisis followed, accounting for 9.88 percent of all risk-related sentences in 2020Q2. In 2021, the direct impact of Covid-19 shifted to concerns about inflation and supply chain issues.
On a global scale, these concerns far outweighed uncertainty related to Russia’s invasion of Ukraine, although the pattern reverses for German firms, where 4.02 percent of risk sentences in 2022Q1 were related to Russia. In our sample, discussions of AI remain a minor risk factor for the average firm. This way, by measuring topic-specific risks, we can make meaningful comparisons about the level of concern firms have regarding one source of risk relative to others.
We believe that such a corporate-text based approach to economic research can be adapted to address a broad spectrum of research questions. The article provides additional examples and applications. With the wealth of available corporate-text data and the continued advancement of computational linguistics tools, we expect that future economic surveillance will depend as much on analyzing these texts as it does on survey data and accounting numbers today.
Another promising recent development we draw attention to is the integration of corporate-text sources. In the article, we showcase a study using the intersection of the full text of patents, job postings, Wikipedia, and earnings call transcripts to map technology development locations and track job demand for new technologies across 51 million job listings from 2010 to 2019 (Kalyani et al. 2024).
This granular data provides insights into the number, location, and skill requirements for jobs linked to emerging technologies. This way, we observe so-called “technology hubs”—geographic locations where early patenting activity in a technology is closely linked to subsequent job growth in both its use and production. This advantage for pioneer locations is especially evident in high-skill jobs associated with the new technology and is found to last for several decades.
In a similar analysis, intersecting patents, job postings, and earnings call transcripts, Bloom et al. (2021) examine the diffusion of 29 disruptive technologies across U.S. locations. They highlight the pivotal role of universities in driving technological progress and the mutually beneficial relationship between academia and industry.
To summarize, corporate-text data (such as earnings call transcripts, patent text, and job postings), when analyzed with accessible computational linguistics tools, offer researchers and policymakers alike a direct means of gaining insights from company executives, financial analysts, and other market participants on economic events. This rich corporate-text data can be collected not only from a wide range of publicly traded companies in the U.S. but also from numerous international firms. Leveraging these granular data to improve economic surveillance is just one way to take advantage of them. Overall, many new opportunities for applying textual methodologies in economic surveillance remain to be explored.
The complete article is available here.
Distribution channels: Education
Legal Disclaimer:
EIN Presswire provides this news content "as is" without warranty of any kind. We do not accept any responsibility or liability for the accuracy, content, images, videos, licenses, completeness, legality, or reliability of the information contained in this article. If you have any complaints or copyright issues related to this article, kindly contact the author above.
Submit your press release